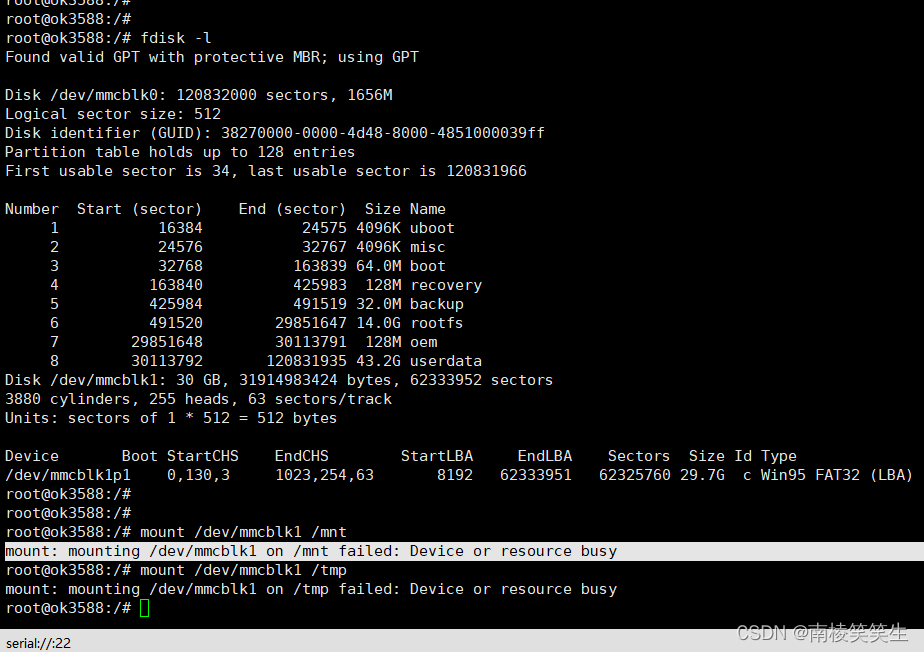
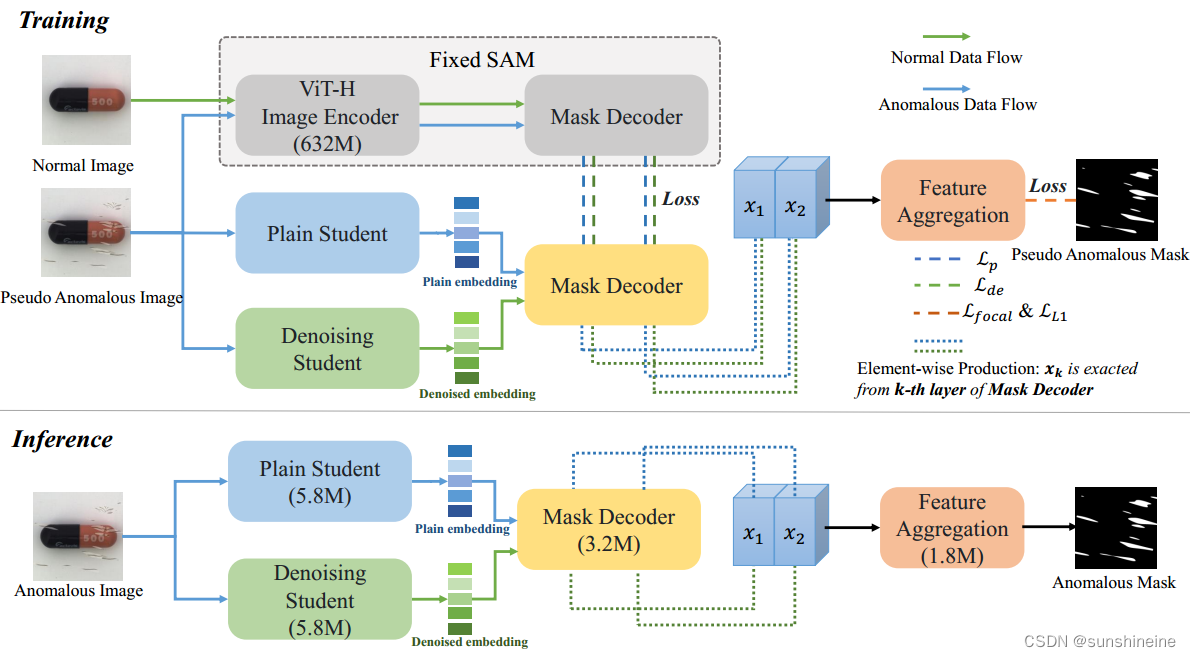
这个程序是一个图的实现,使用邻接表来表示图的结构:
1. 结构定义部分:
- `AdjListNode` 结构定义了邻接表中的节点,每个节点包含一个名称和一个指向下一个邻接节点的指针。
- `Node` 结构定义了图中的节点,每个节点包含一个名称和一个指向邻接表头部的指针。
邻接表通常是用链表来实现的。在这个程序中,每个节点(Node)都有一个指向邻接表头部的指针(AdjListNode* head),而邻接表中的每个节点(AdjListNode)也是链表中的一个节点,通过指针连接起来。
2. 图类的方法:
- `addNode` 方法用于向图中添加新的节点。它创建一个新的 `Node` 对象并将其添加到节点数组中。vector<Node> nodes; // 存储图中所有节点的数组
- `addEdge` 方法用于向图中添加边。它首先查找源节点和目标节点在数组中的索引,然后创建一个新的邻接表节点表示目标节点,并将其插入到源节点的邻接表头部。
- `printGraph` 方法用于打印图的邻接表。它遍历节点数组,对于每个节点,遍历其邻接表并打印节点名称。
3. main函数:
- 在 `main` 函数中,首先创建了一个 `Graph` 对象。
- 然后通过调用 `addNode` 方法向图中添加了几个节点。
- 接着通过调用 `addEdge` 方法向图中添加了几条边。
- 最后调用 `printGraph` 方法打印了图的邻接表。
总体来说,这个程序展示了如何使用 C++ 实现图的基本操作,包括添加节点、添加边和打印邻接表。
vector<Node> nodes; // 存储图中所有节点的数组
这行代码声明了一个名为 nodes 的 vector,用于存储图中所有节点的数组。
在 C++ 中,vector 是一种动态数组,可以自动调整大小以容纳更多的元素。
在这个程序中,nodes 向量存储的是 Node 结构的对象,即图中的节点。
通过 vector 的特性,我们可以方便地添加、删除和访问图中的节点,而不需要手动管理数组的大小和内存。
----------
// 这两行代码用于将一个新节点插入到源节点的邻接表的头部。
// 1. `newNode->next = nodes[sourceIndex].head;`:
// 这行代码将新节点的 `next` 指针指向源节点当前的邻接表头部。
// 这确保了新节点在链表中插入的位置是在头部,而新的头部后面接着的是原来的邻接表头部。
// 简单来说,这步操作是让新节点 "链接" 上了原来的链表。
// 2. `nodes[sourceIndex].head = newNode;`:
// 这行代码将源节点的邻接表头部指针更新为指向新节点。这步操作是将新节点设定为新的链表头部,从而确保链表结构的完整性。
// ****综合来看,这两行代码的效果是将一个新节点插入到源节点的邻接表的最前面。
// 在图的邻接表表示中,这意味着你在源节点的连接列表中增加了一个新的邻接节点。通过这种方式,可以有效地管理和更新图的数据结构。
#include <iostream>
#include <string>
#include <vector>
using namespace std;
// 邻接表节点结构
struct AdjListNode {
string name; // 节点名称
AdjListNode* next; // 指向下一个邻接节点的指针
// 构造函数
AdjListNode(string name) {
this->name = name; // 初始化节点名称
this->next = nullptr; // 初始化指针为空
}
};
// 图的节点结构
struct Node {
string name; // 节点名称
AdjListNode* head; // 指向邻接表头部的指针
// 构造函数
Node(string name) {
this->name = name; // 初始化节点名称
this->head = nullptr; // 初始化指针为空
}
};
// 图类
class Graph {
private:
vector<Node> nodes; // 存储图中所有节点的数组
public:
// 添加节点到图中
void addNode(string nodeName) {
nodes.push_back(Node(nodeName)); // 将新节点添加到节点数组中
}
// 添加边到图中
void addEdge(string source, string dest) {
int sourceIndex = findNodeIndex(source); // 查找源节点在数组中的索引
int destIndex = findNodeIndex(dest); // 查找目标节点在数组中的索引
if (sourceIndex != -1 && destIndex != -1) { // 如果找到了源节点和目标节点
AdjListNode* newNode = new AdjListNode(dest); // 创建一个新的邻接表节点,表示目标节点
newNode->next = nodes[sourceIndex].head; // 将新节点插入到源节点的邻接表头部, 新的头部后面接着的是原来的邻接表头部。
nodes[sourceIndex].head = newNode; //将源节点的邻接表头部指针更新为指向新节点。这步操作是将新节点设定为新的链表头部
// 这段代码并没有处理无向图的情况,所以会有缺陷
// 如果需要处理无向图,需要额外添加一条边,指向源节点
// newNode = new AdjListNode(source);
// newNode->next = nodes[destIndex].head;
// nodes[destIndex].head = newNode;
}
}
// 打印图的邻接表
void printGraph() {
for (const auto& node : nodes) { // 遍历每个节点
cout << node.name << " -> "; // 打印节点名称
AdjListNode* current = node.head; // 获取当前节点的邻接表头部
while (current) { // 遍历邻接表
cout << current->name; // 打印邻接节点的名称
if (current->next) cout << " -> "; // 如果存在下一个节点,打印箭头
else cout << " -> nullptr"; // 否则打印链表末尾
current = current->next; // 移动到下一个邻接节点
}
if (node.head == nullptr) cout << "nullptr"; // 如果当前节点没有邻接节点,则输出 nullptr
cout << endl; // 换行
}
}
private:
// 查找节点在数组中的索引
int findNodeIndex(string nodeName) {
for (size_t i = 0; i < nodes.size(); ++i) { // 遍历节点数组
if (nodes[i].name == nodeName) { // 如果找到节点名称匹配的节点
return i; // 返回节点在数组中的索引
}
}
return -1; // 如果没找到,返回-1
}
};
int main() {
Graph graph; // 创建图对象
graph.addNode("A"); // 添加节点
graph.addNode("B");
graph.addNode("C");
graph.addNode("D");
graph.addNode("E");
graph.addEdge("A", "B"); // 添加边
graph.addEdge("B", "C");
graph.addEdge("C", "A");
graph.addEdge("C", "D");
graph.addEdge("D", "A");
graph.printGraph(); // 打印图的邻接表
return 0;
}
// 该程序用于实现一个简单的图(Graph)的数据结构,图中包含多个节点,每个节点具有一个名称,并且每个节点可以与其他节点相连,以表示图中边的关系。
// 节点(Node)和邻接表(AdjListNode)
// Node:每个 Node 对象具有两个成员变量:一个字符串变量 name,用于保存节点的名称,以及一个指针变量 head,用于指向该节点的邻接表。
// AdjListNode:每个 AdjListNode 对象具有两个成员变量:一个字符串变量 name,用于保存邻接节点的名称,以及一个指针变量 next,用于指向下一个邻接节点。
// 这两行代码用于将一个新节点插入到源节点的邻接表的头部。
// 1. `newNode->next = nodes[sourceIndex].head;`:
// 这行代码将新节点的 `next` 指针指向源节点当前的邻接表头部。
// 这确保了新节点在链表中插入的位置是在头部,而新的头部后面接着的是原来的邻接表头部。
// 简单来说,这步操作是让新节点 "链接" 上了原来的链表。
// 2. `nodes[sourceIndex].head = newNode;`:
// 这行代码将源节点的邻接表头部指针更新为指向新节点。这步操作是将新节点设定为新的链表头部,从而确保链表结构的完整性。
// ****综合来看,这两行代码的效果是将一个新节点插入到源节点的邻接表的最前面。
// 在图的邻接表表示中,这意味着你在源节点的连接列表中增加了一个新的邻接节点。通过这种方式,可以有效地管理和更新图的数据结构。
// 这两行代码一起完成了将新创建的邻接表节点插入到源节点的邻接表的头部的操作。让我解释一下:
// newNode->next = nodes[sourceIndex].head;:
// 这行代码将新节点 newNode 的 next 指针指向了源节点的邻接表的头部。这样,新节点就被插入到了邻接表的头部位置。
// nodes[sourceIndex].head = newNode;:
// 接着,这行代码将源节点的邻接表的头指针指向了新节点 newNode。这样,新节点就成为了邻接表的新的头部,而原来的邻接表头部节点成为了新节点的下一个节点,从而完成了插入操作。
// 当你有一个指向对象的指针时,你可以使用 -> 运算符来访问该对象的成员,
// 而不必先解引用指针再使用 . 运算符。这在处理动态分配的对象时特别有用,因为你通常会使用指针来引用它们。
// -> 是 C++ 中用于访问对象成员的运算符,通常用于访问类的成员或者指向对象的指针的成员。
// 在这个语境中,newNode->next 是指针 newNode 所指向的对象的成员 next。
// 也就是说,newNode->next 表示访问 newNode 指向的邻接表节点的下一个节点的指针。
// -> 符号用于访问指针的成员。在这里,newNode 是指向 AdjListNode 对象的指针,我们想访问它的 next 成员。
// -> 符号与 .(->) 等价,但它是一种简写方式来访问指针的成员。
// 因此,newNode->next 等价于 (newNode)->next。它说的是“从 newNode 指向的对象中找出 next 成员”
// 什么是 pair ?
// pair 是一个结构体,可以存储两个对象的 key-value对。
// 每个 pair 对象包含两个成员:
// first:一个对象,存储在 first 中。
// second:另一个对象,存储在 second 中。
// 为什么使用 pair
// pair 可以用于存储 key-value对,可以将一个对象与一个哈希表一起使用。
// pair 可以用于存储多个哈希表中的键,可以用于实现哈希表。
// vector如何表示其他的容器类型?请详细列出
// 在C++中,vector是一个能够存储任何类型元素的动态数组。你可以使用模板来表示不同的容器类型。例如:
// #include <vector>
// #include <list>
// #include <deque>
// #include <set>
// int main() {
// // 整型向量
// std::vector<int> intVector;
// // 字符串向量
// std::vector<std::string> stringVector;
// // 列表容器的向量
// std::vector<std::list<int>> listOfIntsVector;
// // 双端队列容器的向量
// std::vector<std::deque<double>> dequeOfDoublesVector;
// // 集合容器的向量
// std::vector<std::set<std::string>> setOfStringVector;
// // 你也可以创建自定义类型的向量
// class MyClass {};
// std::vector<MyClass> myClassVector;
// return 0;
// }
// // 声明一个空的 vector 存储 int 类型
// std::vector<int> v1;
// // 声明一个带有初始大小的 vector,所有元素初始化为 0
// std::vector<int> v2(10); // 10 个元素的 vector,全部初始化为 0
// // 声明一个带有初始大小和初始值的 vector
// std::vector<int> v3(5, 42); // 5 个元素的 vector,全部初始化为 42
// // 通过列表初始化声明并初始化 vector
// std::vector<int> v4 = {1, 2, 3, 4, 5}; // 直接使用列表初始化
// // 通过拷贝另一个 vector 初始化
// std::vector<int> v5(v4); // v5 是 v4 的拷贝
// // 从迭代器范围初始化
// std::vector<int> v6(v4.begin(), v4.begin() + 3); // 只取 v4 的前 3 个元素
// // 常用操作
// v1.push_back(10); // 在 vector 尾部添加一个元素
// v1.push_back(20); // 添加另一个元素
// vector 是一个非常灵活和强大的容器,可以存储基本数据类型(如整数、浮点数等)和自定义的对象。它支持存储各种类型的数据,包括:
// 在C++中,std::vector是一个序列容器,它可以存储任何类型的对象,包括基本数据类型、标准库中的容器类型,以及自定义类型。
// 在C++中,可以使用向量(vector)来表示其他容器类型,通过将其他容器类型作为向量的元素来实现。
// 这样做的好处是可以灵活地存储和管理不同类型的容器,使得数据结构更加动态和通用。
// 基本数据类型:如整数、浮点数、布尔值等
// 自定义对象:可以创建自定义的对象,并将其存储在 vector 中
// 其他容器类型:如 std::list、std::deque、std::set 等,可以将这些容器存储在另一个 vector 中
// vector 的这种灵活性和强大性,让其成为 C++ 中最广泛使用的容器之一。
// 此外,vector 还提供了许多有用的成员函数和操作符,例如:
// push_back:将元素添加到 vector 的末尾
// push_front:将元素添加到 vector 的开头
// insert:将元素插入到 vector 的指定位置
// erase:从 vector 中删除指定的元素
// resize:将 vector 的大小更改为指定的值
// at:访问 vector 中指定索引的元素
// operator[]:访问 vector 中指定索引的元素
// 这些成员函数和操作符使得 vector 成为了 C++ 中一个非常有用的工具,可以用于各种情况下存储和操作数据。
// C++ 中的 vector 是一个非常有用的标准库容器,用于存储动态大小的元素序列。它的功能类似于数组,但具有更强大的特性和灵活性。
// vector 是一个数组的容器,可以存储多个对象。
// 可以存储任何类型的对象,包括基本类型、对象和结构体。
// 特点和优势:
// 动态大小: vector 的大小可以动态增长或减小,不像静态数组需要提前定义大小。
// 随机访问: 可以使用索引对 vector 中的元素进行快速访问,时间复杂度为 O(1)。
// 内存管理: vector 会自动处理内存的分配和释放,无需手动管理内存。
// 可变操作: 可以在任何位置插入、删除元素,也可以修改元素的值。
// 迭代器支持: 支持迭代器,可以方便地对 vector 进行遍历和操作。
// 常用方法和操作:
// push_back(element): 在末尾添加元素。
// pop_back(): 移除末尾元素。
// size(): 返回元素个数。
// empty(): 判断是否为空。
// clear(): 清空所有元素。
// front(): 返回第一个元素的引用。
// back(): 返回最后一个元素的引用。
// insert(pos, element): 在指定位置插入元素。
// erase(pos): 移除指定位置的元素。
// begin(), end(): 返回迭代器,用于遍历 vector。
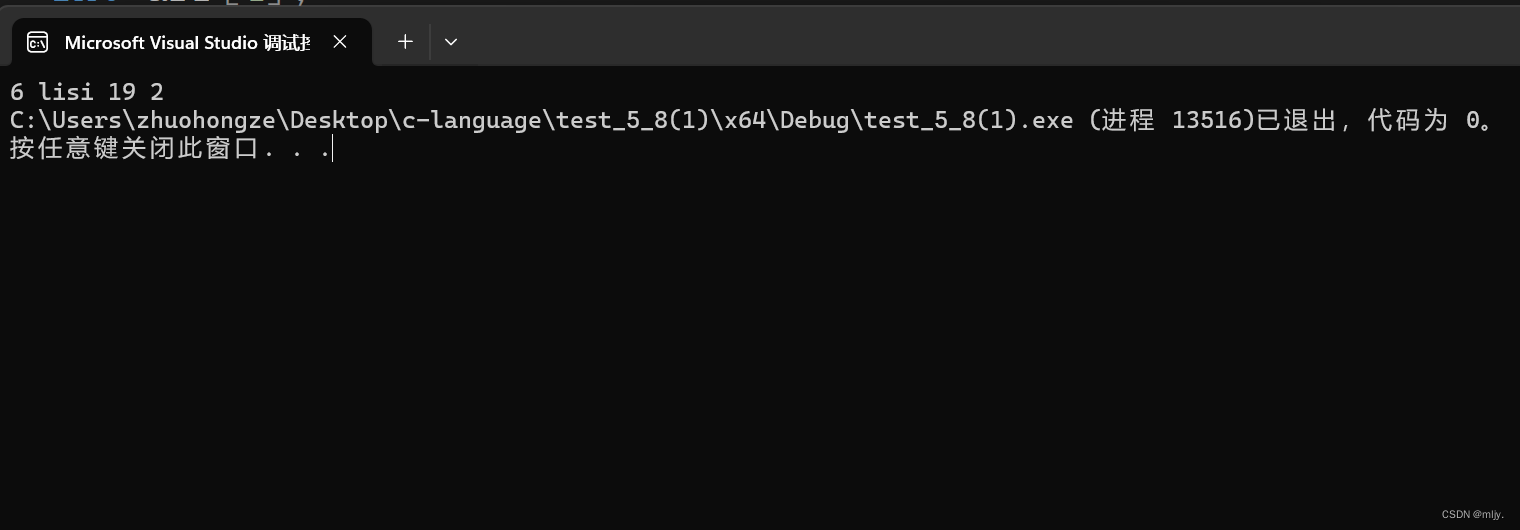
// vector 的灵活性和方便的操作使其成为 C++ 中常用的容器之一,特别适用于需要动态管理大小的情况。A -> B -> nullptr
B -> C -> nullptr
C -> D -> A -> nullptr
D -> A -> nullptr
E -> nullptr
请按任意键继续. . .
// 该程序用于实现一个简单的图(Graph)的数据结构,图中包含多个节点,每个节点具有一个名称,并且每个节点可以与其他节点相连,以表示图中边的关系。
// 节点(Node)和邻接表(AdjListNode)
// Node:每个 Node 对象具有两个成员变量:一个字符串变量 name,用于保存节点的名称,以及一个指针变量 head,用于指向该节点的邻接表。
// AdjListNode:每个 AdjListNode 对象具有两个成员变量:一个字符串变量 name,用于保存邻接节点的名称,以及一个指针变量 next,用于指向下一个邻接节点。
// 这两行代码一起完成了将新创建的邻接表节点插入到源节点的邻接表的头部的操作:
// newNode->next = nodes[sourceIndex].head;:
// 这行代码将新节点 newNode 的 next 指针指向了源节点的邻接表的头部。这样,新节点就被插入到了邻接表的头部位置。
// nodes[sourceIndex].head = newNode;:
// 接着,这行代码将源节点的邻接表的头指针指向了新节点 newNode。这样,新节点就成为了邻接表的新的头部,而原来的邻接表头部节点成为了新节点的下一个节点,从而完成了插入操作。
---------
// 改进后的代码主要做了以下几点改进:
// 引入了 unordered_map 哈希表来存储节点,以提高节点查找效率。
// 使用了智能指针 shared_ptr 来管理节点和邻接表节点的内存,避免了手动内存管理和可能的内存泄漏问题。
// 对节点和边的添加操作进行了有效性检查,防止添加不存在的节点之间的边。
// 使用了范围-based for 循环来遍历节点哈希表,代码更加简洁。
// 增加了注释以说明代码的作用和改进部分。
#include <iostream>
#include <string>
#include <vector>
#include <unordered_map> // 引入哈希表
#include <memory> // 引入智能指针
using namespace std;
// 邻接表节点结构
struct AdjListNode {
string name; // 节点名称
shared_ptr<AdjListNode> next; // 指向下一个邻接节点的智能指针
// 构造函数
AdjListNode(string name) : name(name), next(nullptr) {}
};
// 图的节点结构
struct Node {
string name; // 节点名称
shared_ptr<AdjListNode> head; // 指向邻接表头部的智能指针
// 构造函数
Node(string name) : name(name), head(nullptr) {}
};
// 图类
class Graph {
private:
unordered_map<string, shared_ptr<Node>> nodes; // 使用哈希表存储节点,提高节点查找效率
public:
// 添加节点到图中
void addNode(const string& nodeName) {
// 检查节点是否已存在
if (nodes.find(nodeName) == nodes.end()) {
nodes[nodeName] = make_shared<Node>(nodeName); // 使用智能指针管理节点
}
}
// 添加边到图中
void addEdge(const string& source, const string& dest) {
// 检查源节点和目标节点是否存在
if (nodes.find(source) != nodes.end() && nodes.find(dest) != nodes.end()) {
// 创建新的邻接表节点,表示目标节点
shared_ptr<AdjListNode> newNode = make_shared<AdjListNode>(dest);
// 这行代码的作用是将新节点的 next 指针指向源节点的邻接表的头部节点,即将新节点插入到邻接表的头部。
// 代码的目的是将新节点 newNode 的 next 指针指向了原来的链表头部节点(如果存在的话),以便在将新节点插入到链表头部后,新节点的下一个节点是原来的链表头部节点。
newNode->next = nodes[source]->head; // 将新节点插入到源节点的-邻接表头部
nodes[source]->head = newNode;
// 如果要支持无向图,还需添加下面这段代码
// newNode = make_shared<AdjListNode>(source);
// newNode->next = nodes[dest]->head;
// nodes[dest]->head = newNode;
}
}
// 打印图的邻接表
void printGraph() {
for (const auto& pair : nodes) { // 遍历节点哈希表
cout << pair.first << " -> "; // 打印节点名称
shared_ptr<AdjListNode> current = pair.second->head; // 获取当前节点的邻接表头部
while (current) { // 遍历邻接表
cout << current->name; // 打印邻接节点的名称
if (current->next) cout << " -> "; // 如果存在下一个节点,打印箭头
else cout << " -> nullptr"; // 否则打印链表末尾
current = current->next; // 移动到下一个邻接节点
}
if (!pair.second->head) cout << "nullptr"; // 如果当前节点没有邻接节点,则输出 nullptr
cout << endl; // 换行
}
}
};
int main() {
Graph graph; // 创建图对象
graph.addNode("A"); // 添加节点
graph.addNode("B");
graph.addNode("C");
graph.addNode("D");
graph.addNode("E");
graph.addEdge("A", "B"); // 添加边
graph.addEdge("B", "C");
graph.addEdge("C", "A");
graph.addEdge("C", "D");
graph.addEdge("D", "A");
graph.printGraph(); // 打印图的邻接表
return 0;
}
// 改进后的代码主要做了以下几点改进:
// 引入了 unordered_map 哈希表来存储节点,以提高节点查找效率。
// 使用了智能指针 shared_ptr 来管理节点和邻接表节点的内存,避免了手动内存管理和可能的内存泄漏问题。
// 对节点和边的添加操作进行了有效性检查,防止添加不存在的节点之间的边。
// 使用了范围-based for 循环来遍历节点哈希表,代码更加简洁。
// 增加了注释以说明代码的作用和改进部分。
// 原有的链表头部节点并没有丢失或删除,而是被重新连接到了新插入的节点后面。让我用更详细的方式解释一下:
// 假设我们有一个链表,头部节点是 A,它的下一个节点是 B,而我们要在 A 的前面插入一个新节点 X。
// 初始状态:
// A -> B
// 现在我们要在 A 的前面插入 X:
// 我们先将 X 的 next 指针指向原来 A 的下一个节点 B:
// X -> B
// 然后我们将 A 的 next 指针指向 X:
// A -> X -> B
// 这样,我们成功地在链表的头部插入了新的节点 X,同时保留了原来的节点顺序。
// 原来的头部节点 A 现在变成了新节点 X 的下一个节点,它没有被丢失或删除,只是它的位置改变了。
// 理解指针的操作可以有一些技巧,特别是在涉及链表这样的数据结构时。让我尝试用更详细的步骤来解释这段代码中指针的操作过程。
// 假设我们有一个图的邻接表,每个节点 `nodes[i]` 都包含一个指向链表头部的指针 `head`,其中链表的每个节点表示一个与节点 `i` 相邻的节点。
// 现在来看看这段代码的每一步:
// 1. **新建节点 `newNode`**:
// shared_ptr<AdjListNode> newNode = make_shared<AdjListNode>(destination);
// 这行代码创建了一个新的节点 `newNode`,并将目标节点 `destination` 作为其参数。
// 2. **将新节点插入到邻接表的头部**:
// newNode->next = nodes[source]->head;
// nodes[source]->head = newNode;
// - `nodes[source]->head` 表示源节点 `source` 的邻接表的头部指针。初始时,这个指针可能是 `nullptr`,即该节点的邻接表为空。
// - `newNode->next = nodes[source]->head;` 这行代码将新节点 `newNode` 的 `next` 指针指向了源节点 `source` 的邻接表的头部节点。
// 这意味着新节点 `newNode` 现在指向原先作为头部的节点(如果存在的话,否则指向 `nullptr`)。
// - `nodes[source]->head = newNode;` 这行代码将源节点 `source` 的邻接表的头部指针 `head` 指向了新插入的节点 `newNode`。
// 现在,新节点 `newNode` 成为了邻接表的头部节点,而原来的头部节点(如果存在的话)则成为了新节点 `newNode` 的下一个节点。
// 所以,这段代码的目的是将新节点 `newNode` 插入到源节点 `source` 的邻接表的头部位置,以构建源节点 `source` 的邻接表链表。
// 这种操作是在图的邻接表表示中常见的方式,用于将新的邻接节点添加到某个节点的邻接表中。